In my previous posts I wrote about the upgrade of vCSA (vCenter Server Appliance) from version 5.5 to 6.0.
In all my lab testing the upgrade runs without any errors. On our production site I was doing the upgrade and the migration went fine until the new appliance boots for the first time.
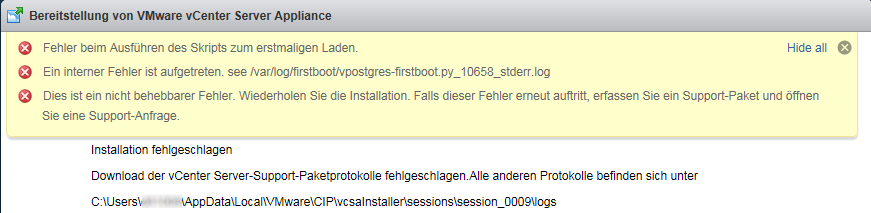
The services start all until the vPostgres database starts. Something in the upgrade script gives back an error. Installation abort and I must boot the old vCSA 5.5.
VMware closed my call, because of an unsupported way getting vCenter Server for Windows to the vCSA 5.5. Everything runs in the vCSA 5.5. The upgrade fails and with the migrated database there is no support.
Fortunately the services on the old vCSA 5.5 came up running and I didn’t have to do a lot of work for rollback.
I’ve searched in VMware KB and community. I’ve made several steps (based on the information from KB and community)
- Set only one DNS server in the upgrade wizard
- Add static binding for the temporary name and IP of vCSA
- Truncate history data on the old side
The logfile vpostgres-firstboot.py_10658_stderr.log don’t give much information.
Severall skipped messages, which were also there in my lab tests, and at the end “Upgrade import step failed” and “vPostgres firstboot(action=firstboot) failed”

The other logs inside the vCSA didn’t show me any curious messages, so I’ve decided to open a call at VMware support.
I will update this post with new information as soon as I become them.
Updates ordered descending:
Update 21.07.2015 14:00
The manager has called me. He excused the late call (is he reading my blog :) ?). We can’t escalate our failure, because our support level (Production Support) does not match to root cause analysis.
Update 21.07.2015 07:00
The ticket ist closed with the last posted reason. I’ve tried to get the manager of the support team, but no more reactions :(
Update 09.07.2015 14:09
Received information from Escalation Engineer. The database error is the result of converting the database from Windows vCenter Server to vCSA.
It’s really sad, because the vCSA 5.5.0 runs perfectly with the converted database.
The Support Engineer told me to set up a new installation of vCSA 6 and connect the ESXi servers to it.
Update 03.07.2015 11:27
The Support Engineer escalates the Request and needs additional data
- database embedded or external?
- database manual changed (vor example converted from Windows vCenter DB)?
- log bundle from vCenter 5.5 (kb.vmware.com/kb/1011641)
Update 03.07.2015 10:40
The VMware support contacted me and wants that I increase the amount of memory in the source vCSA from 8GB to 16GB. If I already have 16GB configured I should set it +4GB.The upgrade wizards runs in the same way and unfortunately in the same error (Memory set to 16GB and after that 20GB for a second test)
Now Support, it’s on you again…
Update 01.07.2015 15:56
The support need some extra time to view all logs I’ve sent.I should check that passwords for root and administrator@vsphere.local are valid and not expired…
Weird, if they were expired, how should I authenticate within the upgrade wizard? :(
Hope I’ll get more information tomorrow.
Update 01.07.2015 09:03 – Call opened
VMware acknowledges Support RequestI’ve uploaded the screenshot, the logs generated from my workstation and the files from /var/log to VMware
Now waiting for response
We have the same problem and we cant find any solution to migrate vCSA 5.5 U2 to vCSA 6.0. New clean install of vCSA 6.0 seems like the only way to deploy it in our environment.
yes, that is what I must do too.
Rename your current vCenter VM in the inventory so the new VM can be created as the same name. Otherwise the vCSA folders on the LUNs will not match.
Hi Lyle,
yes, this is a solution to get the same name for a virtual machine in the inventory and NETBIOS/DNS-Name. But the Problem with firstboot isn’t solved by this…
Hi Alexander, i have this same problem, you have a another information about how to fix it?, i will tray to rename the old appliance 5.5 to have the same name on the newone. Regards from Venezuela!
Hi!
I’ve solved this problem for at least my setup. I noticed that the vPostgres logs claimed that there was no diskspace left when creating indexes during the firstboot process.
When I set vCenter to deploy the option with 4 cores, 150GB HDD and 16GB RAM it worked however, but I still wanted the tiny one. So I truncated the event and task tables as outlined here: https://communities.vmware.com/message/623697
Then after running the vacuum process and confirmed vCenter was still working, I ran the upgrade again while carefully watching the process and it indeed upgraded.
Hi Cluez,
thanks for your reply. I’ve made the same test with our database, but the error was still there. I’ve hoped this could be my solution to, but it wasn’t.
Thanks for your help.
Hi Gabriel,
the rename of the “old” appliance is not necessary.
You can rename your old appliance in *_old in vCenter. So you can install the new appliance with the correct name.
But the Error didn’t come from a wrong name in the VM Name in vCenter Server.
Best wishes to Venezuela! :)
Ran into the same issue. Exact same error in the log you show.
Was a combination of a few things
1. TIDBIT 6 from this post: http://www.virtuallyghetto.com/2015/09/handy-tidbits-workarounds-for-the-vcs-to-vcsa-migration-fling.html
2. Bad history data. bad data in the event/history tables.
Even though I told the upgrade wizard to not migrate historical data it did not like something.
KB1007453 was followed to truncate all data to 0 days.
I also ran this on the source server for good measure.
/opt/vmware/vpostgres/1.0/bin/psql -d VCDB vc
TRUNCATE TABLE vpx_event CASCADE;
Upgrade to 6.0 then went without a hitch.
Hi. I ran into the same issue as well.
I found the following log entries in /var/log/vmware/vpostgres/postgresql-10.log:
2016-03-10 17:10:26.658 UTC 56e1aa64.4691 11563 VCDB postgres ERROR: insert or update on table “vpx_entity_last_event” violates foreign key constraint “fk_vpx_last_event_event”
2016-03-10 17:10:26.658 UTC 56e1aa64.4691 11563 VCDB postgres DETAIL: Key (last_event_id)=(32354) is not present in table “vpx_event”.
2016-03-10 17:10:26.658 UTC 56e1aa64.4691 11563 VCDB postgres STATEMENT: ALTER TABLE vpx_entity_last_event ADD CONSTRAINT fk_vpx_last_event_event FOREIGN KEY (last_event_id) REFERENCES vpx_event(event_id) ON DELETE CASCADE;
I then checked if both records for that event ID were present in both tables on old appliance:
/opt/vmware/vpostgres/1.0/bin/psql -U postgres -d VCDB
VCDB=# select event_id From vpx_event where event_id = 32354;
event_id
———-
32354
(1 row)
VCDB=# select * From vpx_entity_last_event where last_event_id = 32354;
entity_id | event_type | last_event_id
———–+———————————-+—————
10 | vim.event.ExitedStandbyModeEvent | 32354
(1 row)
So records were OK on old appliance.
I then started to suspect the new appliance was importing data in table vpx_entity_last_event without first importing data in vpx_event.
And it seems indeed that when “Migrate Performance & other historical data” is not checked at step “4. Connect to source appliance” of the deployment process, data from vpx_event is not migrated to the new appliance.
The trick on my side was simply to check “Migrate Performance & other historical data” to have Postgre importing data from vpx_event table and not crashing on that foreign key constraint issue…